Publications
2026
- Survey of Vision-Language-Action Models for Embodied Manipulation面向具身操作的视觉-语言-动作模型综述Haoran Li, Yuhui Chen, Wenbo Cui, Weiheng Liu, Kai Liu, Mingcai Zhou, Zhengtao Zhang, and Dongbin ZhaoIEEE/CAA Journal of Automatica Sinica 自动化学报, Jan 2026
Embodied intelligence systems, which enhance agent capabilities through continuous environment interactions, have garnered significant attention from both academia and industry. Vision-Language-Action models, inspired by advancements in large foundation models, serve as universal robotic control frameworks that substantially improve agent-environment interaction capabilities in embodied intelligence systems. This expansion has broadened application scenarios for embodied AI robots. This survey comprehensively reviews VLA models for embodied manipulation. Firstly, it chronicles the developmental trajectory of VLA architectures. Subsequently, we conduct a detailed analysis of current research across 5 critical dimensions: VLA model structures, training datasets, pre-training methods, post-training methods, and model evaluation. Finally, we synthesize key challenges in VLA development and real-world deployment, while outlining promising future research directions.
具身智能系统通过与环境的连续交互来增强智能体的能力,近年来在学术界和工业界都受到了广泛关注。受大型基础模型发展的启发,视觉-语言-动作(VLA)模型作为通用的机器人控制框架,显著提升了具身智能系统中智能体与环境交互的能力。这一扩展为具身人工智能机器人开辟了更广泛的应用场景。本文全面回顾了面向具身操作的VLA模型。首先,回顾了VLA架构的发展历程。随后,对当前研究在5个关键维度上进行了详细分析:VLA模型结构、训练数据集、预训练方法、后训练方法和模型评估。最后,总结了VLA发展和实际部署中的关键挑战,并概述了未来研究方向。
- Under Review
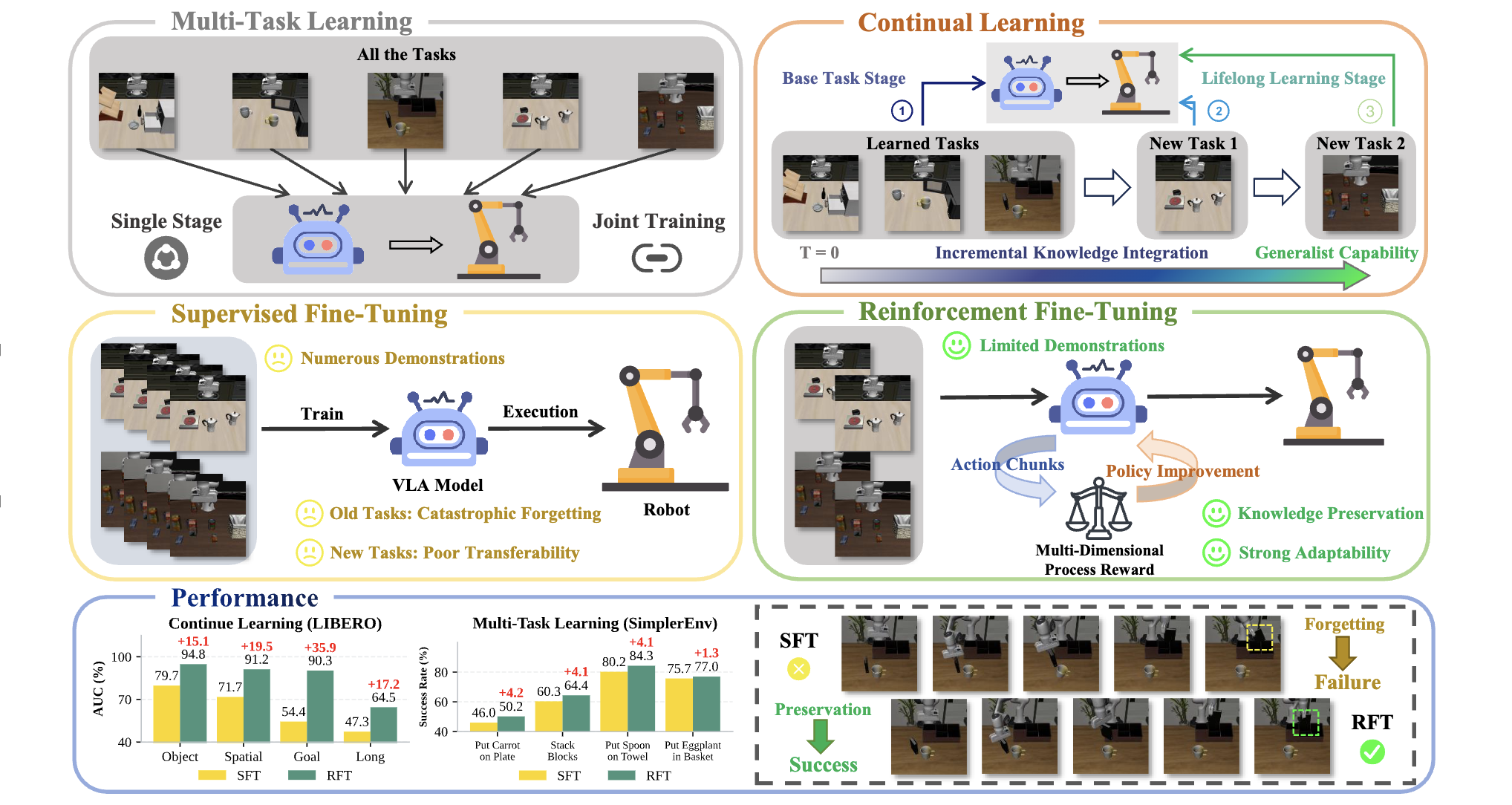 Towards Long-Lived Robots: Continual Learning VLA Models via Reinforcement Fine-TuningYuan Liu, Haoran Li, Shuai Tian, Yuxing Qin, Yuhui Chen, Yupeng Zheng, Yongzhen Huang, and Dongbin ZhaoFeb 2026
Towards Long-Lived Robots: Continual Learning VLA Models via Reinforcement Fine-TuningYuan Liu, Haoran Li, Shuai Tian, Yuxing Qin, Yuhui Chen, Yupeng Zheng, Yongzhen Huang, and Dongbin ZhaoFeb 2026Pretrained on large-scale and diverse datasets, VLA models demonstrate strong generalization and adaptability as general-purpose robotic policies. However, Supervised Fine-Tuning (SFT), which serves as the primary mechanism for adapting VLAs to downstream domains, requires substantial amounts of task-specific data and is prone to catastrophic forgetting. To address these limitations, we propose LifeLong-RFT, a simple yet effective Reinforcement Fine-Tuning (RFT) strategy for VLA models independent of online environmental feedback and pre-trained reward models. By integrating chunking-level on-policy reinforcement learning with the proposed Multi-Dimensional Process Reward (MDPR) mechanism, LifeLong-RFT quantifies the heterogeneous contributions of intermediate action chunks across three dimensions to facilitate policy optimization. Specifically, (1) the Quantized Action Consistency Reward (QACR) ensures accurate action prediction within the discrete action space; (2) the Continuous Trajectory Alignment Reward (CTAR) aligns decoded continuous action chunks with reference trajectories to ensure precise control; (3) the Format Compliance Reward (FCR) guarantees the structural validity of outputs. Comprehensive experiments across SimplerEnv, LIBERO, and real-world tasks demonstrate that LifeLong-RFT exhibits strong performance in multi-task learning. Furthermore, for continual learning on the LIBERO benchmark, our method achieves a 22% gain in average success rate over SFT, while effectively adapting to new tasks using only 20% of the training data. Overall, our method provides a promising post-training paradigm for VLAs.
- Under Review
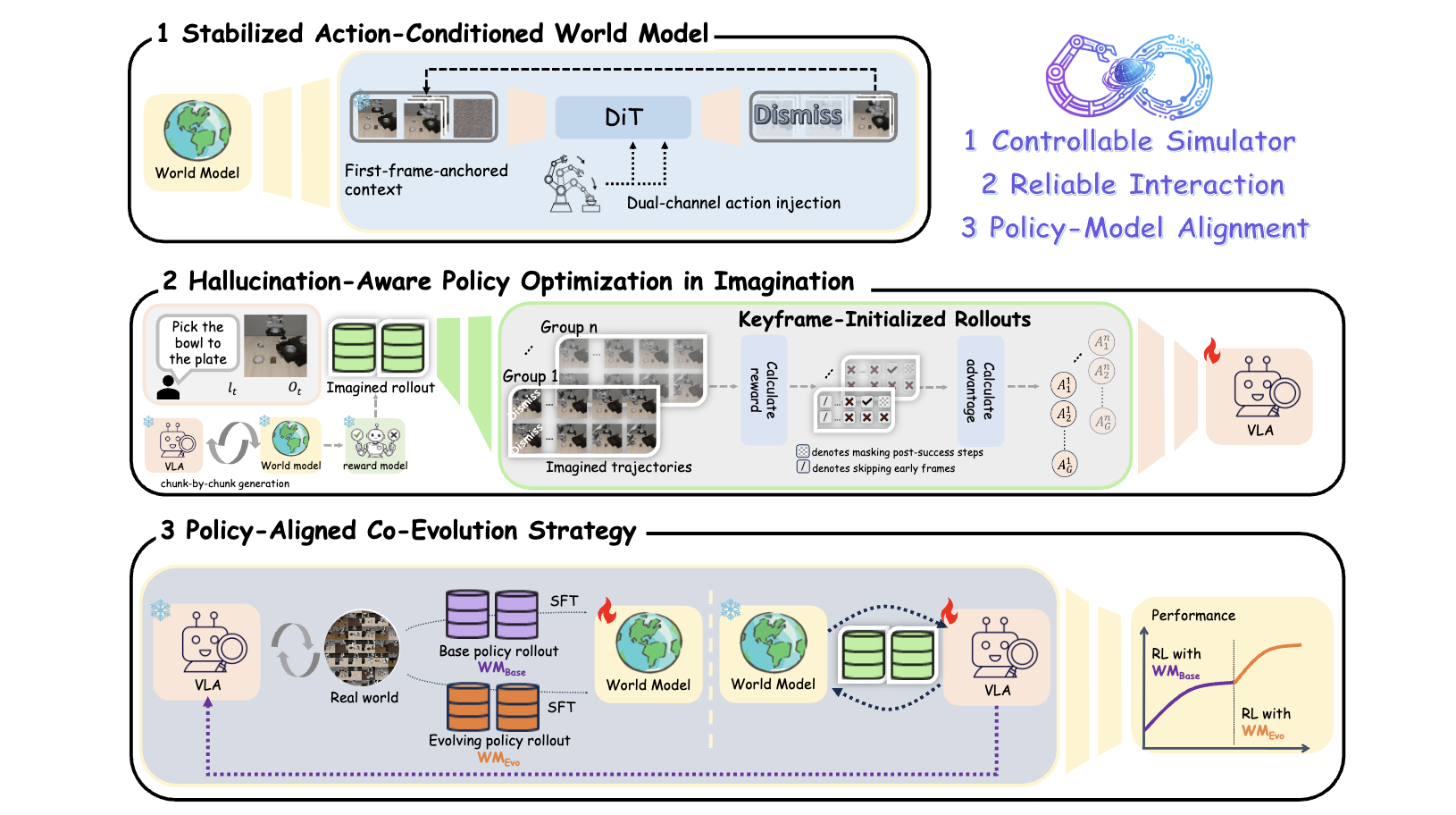 WoVR: World Models as Reliable Simulators for Post-Training VLA Policies with RLZhennan Jiang , Shangqing Zhou , Yutong Jiang, Zefang Huang, Mingjie Wei, Yuhui Chen , Tianxing Zhou, Zhen Guo, Hao Lin , Quanlu Zhang , Yu Wang, Haoran Li, Chao Yu, and Dongbin ZhaoFeb 2026
WoVR: World Models as Reliable Simulators for Post-Training VLA Policies with RLZhennan Jiang , Shangqing Zhou , Yutong Jiang, Zefang Huang, Mingjie Wei, Yuhui Chen , Tianxing Zhou, Zhen Guo, Hao Lin , Quanlu Zhang , Yu Wang, Haoran Li, Chao Yu, and Dongbin ZhaoFeb 2026Reinforcement learning (RL) promises to unlock capabilities beyond imitation learning for Vision–Language–Action (VLA) models, but its requirement for massive real-world interaction prevents direct deployment on physical robots. Recent work attempts to use learned world models as simulators for policy optimization, yet closed-loop imagined rollouts inevitably suffer from hallucination and long-horizon error accumulation. Such errors do not merely degrade visual fidelity—they corrupt the optimization signal, encouraging policies to exploit model inaccuracies rather than genuine task progress. We propose WoVR, a reliable world-model-based reinforcement learning framework for post-training VLA policies. Instead of assuming a faithful world model, WoVR explicitly regulates how RL interacts with imperfect imagined dynamics. It improves rollout stability through a controllable action-conditioned video world model, reshapes imagined interaction to reduce effective error depth via Keyframe-Initialized Rollouts, and maintains policy–simulator alignment through World Model-Policy co-evolution. Extensive experiments on LIBERO benchmarks and real-world robotic manipulation demonstrate that WoVR enables stable long-horizon imagined rollouts and effective policy optimization, improving average LIBERO success from 39.95% to 69.2% (+29.3 points) and real-robot success from 61.7% to 91.7% (+30.0 points). These results show that learned world models can serve as practical simulators for reinforcement learning when hallucination is explicitly controlled.
- Under Review
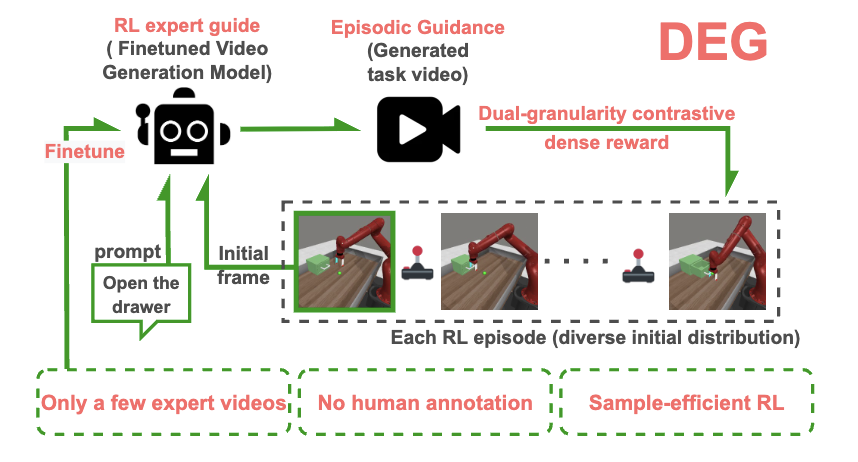 Dual-Granularity Contrastive Reward via Generated Episodic Guidance for Efficient Embodied RLXin Liu , Yixuan Li, Yuhui Chen, Yuxing Qin, Haoran Li, and Dongbin ZhaoFeb 2026
Dual-Granularity Contrastive Reward via Generated Episodic Guidance for Efficient Embodied RLXin Liu , Yixuan Li, Yuhui Chen, Yuxing Qin, Haoran Li, and Dongbin ZhaoFeb 2026Designing suitable rewards poses a significant challenge in reinforcement learning (RL), especially for embodied manipulation. Trajectory success rewards are suitable for human judges or model fitting, but the sparsity severely limits RL sample efficiency. While recent methods have effectively improved RL via dense rewards, they rely heavily on high-quality human-annotated data or abundant expert supervision. To tackle these issues, this paper proposes Dual-granularity contrastive reward via generated Episodic Guidance (DEG), a novel framework to seek sampleefficient dense rewards without requiring human annotations or extensive supervision. Leveraging the prior knowledge of large video generation models, DEG only needs a small number of expert videos for domain adaptation to generate dedicated task guidance for each RL episode. Then, the proposed dual-granularity reward that balances coarse-grained exploration and fine-grained matching, will guide the agent to efficiently approximate the generated guidance video sequentially in the contrastive self-supervised latent space, and finally complete the target task. Extensive experiments on 18 diverse tasks across both simulation and real-world settings show that DEG can not only serve as an efficient exploration stimulus to help the agent quickly discover sparse success rewards, but also guide effective RL and stable policy convergence independently.
- TeViR: Text-to-Video Reward with Diffusion Models for Efficient Reinforcement LearningIEEE Transactions on Systems, Man, and Cybernetics: Systems, Feb 2026
Developing scalable and generalizable reward engineering for reinforcement learning (RL) is crucial for creating general-purpose agents, especially in the challenging domain of robotic manipulation. While recent advances in reward engineering with Vision-Language Models (VLMs) have shown promise, their sparse reward nature significantly limits sample efficiency. This paper introduces TeViR, a novel method that leverages a pre-trained text-to-video diffusion model to generate dense rewards by comparing the predicted image sequence with current observations. Experimental results across 11 complex robotic tasks demonstrate that TeViR outperforms traditional methods leveraging sparse rewards and other state-of-the-art (SOTA) methods, achieving better sample efficiency and performance without ground truth environmental rewards. TeViR’s ability to efficiently guide agents in complex environments highlights its potential to advance reinforcement learning applications in robotic manipulation.
- QDepth-VLA: Quantized Depth Prediction as Auxiliary Supervision for Vision-Language-Action ModelsYixuan Li, Yuhui Chen, Mingcai Zhou, and Haoran LiIn The 25th International Conference on Autonomous Agents and Multiagent Systems, AAMAS , May 2026
Spatial perception and reasoning are crucial for Vision-Language-Action (VLA) models to accomplish fine-grained manipulation tasks. However, existing approaches often lack the ability to understand and reason over the essential 3D structures necessary for precise control. To address this limitation, we propose QDepth-VLA, a general framework that augments VLA models with an auxiliary depth prediction task. A dedicated depth expert is designed to predict quantized latent tokens of depth maps obtained from a VQ-VAE encoder, enabling the model to learn depth-aware representations that capture critical geometric cues. Experimental results on the simulation benchmarks and real-world tasks demonstrate that QDepth-VLA yields strong spatial reasoning and competitive performance on manipulation tasks.
- CLAR: Learning 3D Representations for Robotic Manipulation by Fusing Masked Reconstruction with Multi-Level Contrastive AlignmentIn IEEE International Conference on Robotics and Automation, ICRA , Jul 2026
Building a robust perception module is crucial for visuomotor policy learning. While recent methods incorporate pre-trained 2D foundation models into robotic perception modules to leverage their strong semantic understanding, they struggle to capture 3D spatial information and generalize across diverse camera viewpoints. These limitations hinder the policy’s effectiveness, especially in fine-grained robotic manipulation scenarios. To address these challenges, we propose CL3R, a novel 3D pre-training framework designed to enhance robotic manipulation policies. Our method integrates both spatial awareness and semantic understanding by employing a point cloud Masked Autoencoder to learn rich 3D representations while leveraging pre-trained 2D foundation models through contrastive learning for efficient semantic knowledge transfer. Additionally, we propose a 3D visual representation pre-training framework for robotic tasks. By unifying coordinate systems across datasets and introducing random fusion of multi-view point clouds, we mitigate camera view ambiguity and improve generalization, enabling robust perception from novel viewpoints at test time. Extensive experiments in both simulation and the real world demonstrate the superiority of our method, highlighting its effectiveness in visuomotor policy learning for robotic manipulation.






2025
- ConRFT: A Reinforced Fine-tuning Method for VLA Models via Consistency PolicyYuhui Chen, Shuai Tian , Yingting Zhou, Shugao Liu, Haoran Li, and Dongbin ZhaoIn Robotics: Science and Systems XXI, RSS , Jun 2025
Vision-Language-Action (VLA) models have shown substantial potential in real-world robotic manipulation. However, fine-tuning these models through supervised learning struggles to achieve robust performance due to limited, inconsistent demonstrations, especially in contact-rich environments. In this paper, we propose a reinforced fine-tuning approach for VLA models, named ConRFT, which consists of offline and online fine-tuning with a unified consistency-based training objective, to address these challenges. In the offline stage, our method integrates behavior cloning and Q-learning to effectively extract policy from a small set of demonstrations and stabilize value estimating. In the online stage, the VLA model is further fine-tuned via consistency policy, with human interventions to ensure safe exploration and high sample efficiency. We evaluate our approach on eight diverse real-world manipulation tasks. It achieves an average success rate of 96.3 % within 45–90 minutes of online fine-tuning, outperforming prior supervised methods with a 144 % improvement in success rate and 1.9x shorter episode length. This work highlights the potential of integrating reinforcement learning to enhance the performance of VLA models for real-world robotic applications.

2024
- Generalizing Consistency Policy to Visual RL with Prioritized Proximal Experience RegularizationIn The 38th Annual Conference on Neural Information Processing Systems, NIPS , Sep 2024
With high-dimensional state spaces, visual reinforcement learning (RL) faces significant challenges in exploitation and exploration, resulting in low sample efficiency and training stability. As a time-efficient diffusion model, although consistency models have been validated in online state-based RL, it is still an open question whether it can be extended to visual RL. In this paper, we investigate the impact of non-stationary distribution and the actor-critic framework on consistency policy in online RL, and find that consistency policy was unstable during the training, especially in visual RL with the high-dimensional state space. To this end, we suggest sample-based entropy regularization to stabilize the policy training, and propose a consistency policy with prioritized proximal experience regularization (CP3ER) to improve sample efficiency. CP3ER achieves new state-of-the-art (SOTA) performance in 21 tasks across DeepMind control suite and Meta-world. To our knowledge, CP3ER is the first method to apply diffusion/consistency models to visual RL and demonstrates the potential of consistency models in visual RL.
- Boosting Continuous Control with Consistency PolicyYuhui Chen, Haoran Li, and Dongbin ZhaoIn The 23rd International Conference on Autonomous Agents and Multiagent Systems, AAMAS , May 2024
Due to its training stability and strong expression, the diffusion model has attracted considerable attention in offline reinforcement learning. However, several challenges have also come with it: 1) The demand for a large number of diffusion steps makes the diffusion-model-based methods time inefficient and limits their applications in real-time control; 2) How to achieve policy improvement with accurate guidance for diffusion model-based policy is still an open problem. Inspired by the consistency model, we propose a novel time-efficiency method named Consistency Policy with Q-Learning (CPQL), which derives action from noise by a single step. By establishing a mapping from the reverse diffusion trajectories to the desired policy, we simultaneously address the issues of time efficiency and inaccurate guidance when updating diffusion model-based policy with the learned Q-function. We demonstrate that CPQL can achieve policy improvement with accurate guidance for offline reinforcement learning, and can be seamlessly extended for online RL tasks. Experimental results indicate that CPQL achieves new state-of-the-art performance on 11 offline and 21 online tasks, significantly improving inference speed by nearly 45 times compared to Diffusion-QL.

